
A brand new accelerator chip referred to as “Hiddenite” that may obtain state-of-the-art accuracy within the calculation of sparse “hidden neural networks” with decrease computational burdens has now been developed by Tokyo Tech researchers. By using the proposed on-chip mannequin development, which is the mix of weight era and “supermask” enlargement, the Hiddenite chip drastically reduces exterior reminiscence entry for enhanced computational effectivity.
Deep neural networks (DNNs) are a fancy piece of machine studying structure for AI (synthetic studying) that require quite a few parameters to be taught to foretell outputs. DNNs can, nonetheless, be “pruned,” thereby lowering the computational burden and mannequin measurement. A number of years in the past, the “lottery ticket speculation” took the machine studying world by storm. The speculation acknowledged that a randomly initialized DNN comprises subnetworks that obtain accuracy equal to the unique DNN after coaching. The bigger the community, the extra “lottery tickets” for profitable optimization. These lottery tickets thus enable “pruned” sparse neural networks to attain accuracies equal to extra advanced, “dense” networks, thereby lowering total computational burdens and energy consumptions.
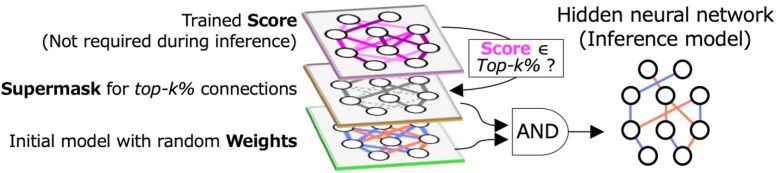
Determine 1. HNNs discover sparse subnetworks which obtain equal accuracy to the unique dense educated mannequin. Credit score: Masato Motomura from Tokyo Tech
One method to search out such subnetworks is the hidden neural community (HNN) algorithm, which makes use of AND logic (the place the output is barely excessive when all of the inputs are excessive) on the initialized random weights and a “binary masks” referred to as a “supermask” (Fig. 1). The supermask, outlined by the top-k% highest scores, denotes the unselected and chosen connections as 0 and 1, respectively. The HNN helps scale back computational effectivity from the software program aspect. Nevertheless, the computation of neural networks additionally requires enhancements within the hardware elements.
Conventional DNN accelerators provide excessive efficiency, however they don't contemplate the facility consumption brought on by exterior reminiscence entry. Now, researchers from Tokyo Institute of Expertise (Tokyo Tech), led by Professors Jaehoon Yu and Masato Motomura, have developed a brand new accelerator chip referred to as “Hiddenite,” which might calculate hidden neural networks with drastically improved energy consumption. “Decreasing the exterior reminiscence entry is the important thing to lowering energy consumption. At the moment, attaining excessive inference accuracy requires massive fashions. However this will increase exterior reminiscence entry to load mannequin parameters. Our predominant motivation behind the event of Hiddenite was to scale back this exterior reminiscence entry,” explains Prof. Motomura. Their research will function within the upcoming Worldwide Strong-State Circuits Convention (ISSCC) 2022, a prestigious worldwide convention showcasing the pinnacles of feat in built-in circuits.
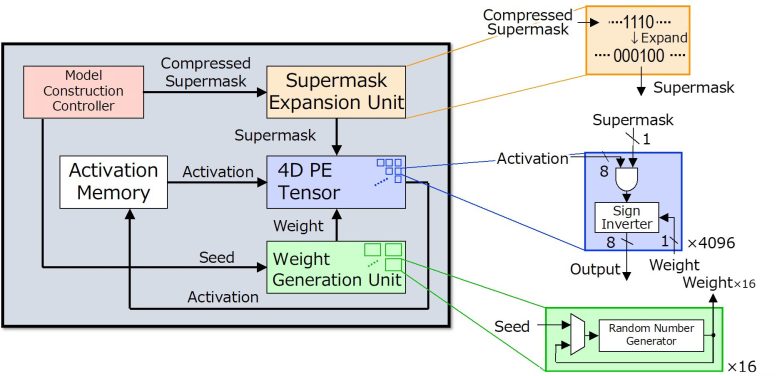
Determine 2. The brand new Hiddenite chip presents on-chip weight era and on-chip “supermask enlargement” to scale back exterior reminiscence entry for loading mannequin parameters. Credit score: Masato Motomura from Tokyo Tech
“Hiddenite” stands for Hidden Neural Community Inference Tensor Engine and is the primary HNN inference chip. The Hiddenite structure (Fig. 2) presents three-fold advantages to scale back exterior reminiscence entry and obtain excessive power effectivity. The primary is that it presents the on-chip weight era for re-generating weights through the use of a random quantity generator. This eliminates the necessity to entry the exterior reminiscence and retailer the weights. The second profit is the supply of the “on-chip supermask enlargement,” which reduces the variety of supermasks that have to be loaded by the accelerator. The third enchancment supplied by the Hiddenite chip is the high-density four-dimensional (4D) parallel processor that maximizes knowledge re-use in the course of the computational course of, thereby bettering effectivity.

Determine 3. Fabricated utilizing 40nm know-how, the core of the chip space is barely 4.36 sq. millimeters. Credit score: Masato Motomura from Tokyo Tech
“The primary two elements are what set the Hiddenite chip other than current DNN inference accelerators,” reveals Prof. Motomura. “Furthermore, we additionally launched a brand new coaching methodology for hidden neural networks, referred to as ‘rating distillation,’ through which the standard data distillation weights are distilled into the scores as a result of hidden neural networks by no means replace the weights. The accuracy utilizing rating distillation is akin to the binary mannequin whereas being half the scale of the binary mannequin.”
Primarily based on the hiddenite structure, the group has designed, fabricated, and measured a prototype chip with Taiwan Semiconductor Manufacturing Firm’s (TSMC) 40nm course of (Fig. 3). The chip is barely 3mm x 3mm and handles 4,096 MAC (multiply-and-accumulate) operations without delay. It achieves a state-of-the-art stage of computational effectivity, as much as 34.8 trillion or tera operations per second (TOPS) per Watt of energy, whereas lowering the quantity of mannequin switch to half that of binarized networks.
These findings and their profitable exhibition in an actual silicon chip are positive to trigger one other paradigm shift on the earth of machine studying, paving the way in which for sooner, extra environment friendly, and in the end extra environment-friendly computing.
Post a Comment